

Introduction
In the evolving world of AI, LLama 2 marks a pivotal advancement. Building on LLama 1’s legacy, it offers enhanced capabilities and adaptability.
This article explores LLama 2’s models, each tailored for specific tasks, and underscores the crucial role of fine-tuning in optimizing its performance for real-world applications. We navigate through the fine-tuning process, from data handling to parameter adjustment, highlighting the challenges and strategies to fully leverage this state-of-the-art technology.
Background on LLama 2
LLama 2 represents a significant leap in the field of artificial intelligence and machine learning, building on the foundations laid by its predecessor, LLama 1. Developed to address more complex and diverse AI tasks, LLama 2 marks a notable advancement in terms of capability, efficiency, and adaptability.
LLama 1: The Precursor
LLama 1 served as a pivotal model in AI, introducing innovative approaches to machine learning and data processing. It set a benchmark for natural language understanding and generation, and other AI-driven tasks. Despite its successes, the evolving demands of AI applications necessitated an upgrade, leading to the development of LLama 2.
Introduction of LLama 2
LLama 2, with its enhanced architecture and improved algorithms, surpasses LLama 1 in both speed and accuracy. It is designed to handle more complex datasets and deliver more precise outcomes. The model’s ability to learn from a broader range of data sources allows for more nuanced and sophisticated AI applications.
Advancements Over LLama 1
LLama 2’s advancements are not just in scale but also in the quality of its algorithms and learning processes. It exhibits an improved understanding of context in language processing and a more effective integration of different types of data. These enhancements make LLama 2 a versatile and powerful tool in the AI toolkit, capable of addressing a wider array of challenges than LLama 1.
Variants of LLama 2
Recognizing the diverse needs of different AI applications, LLama 2 is available in various models, each tailored to specific tasks or levels of complexity. These variants range from smaller, more efficient models suitable for less demanding tasks, to larger, more powerful versions designed for highly complex AI challenges.
Here is a comparison table for its different models , highlighting their training hours, key characteristics, and ideal use cases:
| Model | GPU Hours Trained | Key Characteristics | Ideal Use Cases |
| LLama 2 7B | 184,000 | Smallest and most compact, requires more world knowledge, excellent in text comprehension, ideal for enterprise chatbots and custom data training. | Enterprise chatbots, training on custom data, comprehension-focused applications. |
| LLama 2 13B | 368,000 | Balances size, comprehension, and world knowledge, trained on a larger dataset, suitable for web applications, content writing, and SEO studies. | Web applications, advanced content writing, SEO-based studies. |
| LLama 2 70B | 1,720,000 | Maximum world knowledge and comprehension, vast number of parameters, scalable for large LLM architectures, ideal for education and e-commerce applications. | Education, e-commerce, scalable applications, complex LLM tasks. |
The flexibility in choosing a variant allows users to select a model that best fits their computational capabilities and task requirements.
The Importance of Fine-Tuning LLama 2
Fine-tuning LLama 2, a sophisticated AI model, is a critical step in maximizing its effectiveness and ensuring its applicability to specific tasks or challenges. This process, which involves making precise adjustments to the model’s parameters and training it on task-specific data, holds significant importance for several reasons:
- Tailoring to Specific Applications: While LLama 2 is designed as a versatile and powerful AI model, fine-tuning allows it to be specifically adapted to different applications, ranging from natural language processing to complex problem-solving in various industries. This customization ensures that LLama 2 can perform optimally in diverse environments, whether it’s understanding industry-specific jargon or analyzing unique datasets.
- Enhancing Model Performance and Accuracy: Through fine-tuning, LLama 2 can even achieve higher levels of accuracy and efficiency. This is particularly important in fields where precision is critical, such as healthcare, finance, and autonomous systems. By adjusting the model to focus on relevant features of a specific task, fine-tuning reduces errors and improves the reliability of the model’s outputs.
- Addressing Data Scarcity and Overfitting: In scenarios where there is limited task-specific data available, fine-tuning LLama 2 is especially beneficial. It allows the model to learn effectively from smaller datasets, mitigating the risk of overfitting which can occur when a model is trained too closely on a limited dataset.
Fine-Tuning Process for LLama 2
Fine-tuning LLama 2, an advanced AI model, involves a meticulous process tailored to enhance its performance for specific tasks. This process typically consists of data preparation, parameter adjustment, and model training, each playing a critical role in optimizing the model’s capabilities.
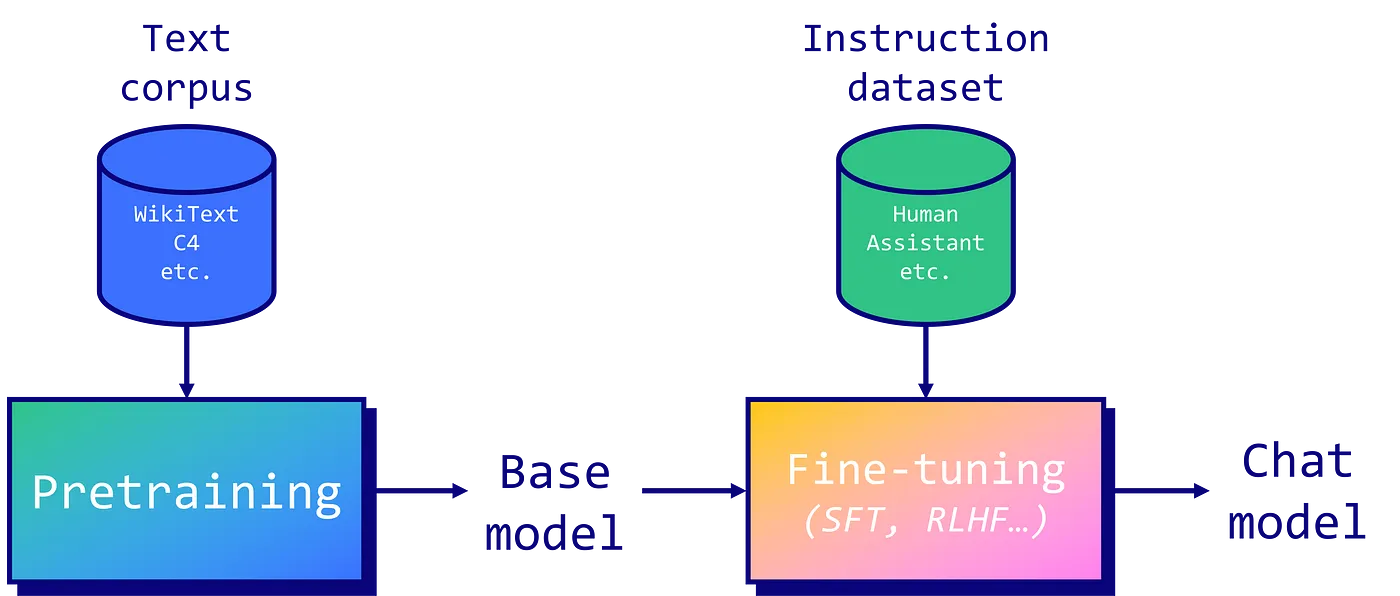
- Data Preparation: The foundation of fine-tuning begins with data preparation. For LLama 2, this involves curating a dataset that is closely aligned with the desired output. The data must be representative of the real-world scenarios where the model will be applied. This includes a diverse range of examples and scenarios to ensure comprehensive learning. Careful annotation and data cleansing are crucial to minimize biases and errors in the training set. Example of Data Format
ReviewText, SentimentLabel “I love this product, it works great!”, Positive
“Terrible experience, the product broke after one use.”, Negative
- Parameter Adjustment: LLama 2 comes with a predefined set of parameters that guide its learning process. Fine-tuning requires adjusting these parameters to better suit the specific needs of the task. This might include modifying the learning rate, the number of layers involved in processing, or even the activation functions. The challenge here is to find the right balance that maximizes learning efficiency without overfitting the model to the training data.
- Model Training: The training phase involves feeding the prepared data into LLama 2 and allowing it to learn from this data. This step is iterative, with the model gradually improving its predictions. It’s essential to monitor the model’s performance throughout this process to ensure it is learning correctly and making accurate predictions. Moreover, make sure to manually check the model’s new output with the previous output.
Unique Challenges: Fine-tuning LLama 2 presents specific challenges, primarily due to its complex architecture. Ensuring that the model does not lose its general capabilities while being fine-tuned for a specific task is a delicate balance. There’s also the risk of overfitting, where the model performs well on the training data but poorly on new, unseen data. Additionally, due to the size and complexity of the model, fine-tuning requires substantial computational resources, and thousands if not millions of data points, which can be a limitation for some users.
Conclusion
LLama 2 exemplifies the evolution of AI, blending flexibility with precision for diverse tasks. This exploration has shown that fine-tuning is key to harnessing its full potential, transforming it into a specialized asset for various applications.it’s adaptability and advanced capabilities position it as a transformative force in the AI landscape, ready to tackle complex, real-world challenges.