

Large language models (LLMs) represent one of the most exciting frontiers in artificial intelligence today. Powered by deep learning on massive datasets, these models can generate amazingly human-like text and perform a variety of language tasks. In this post, we’ll explore the capabilities of LLMs at a high level to demystify what makes them tick and why they’re becoming so pervasive.
What Can Large Language Models Do?
Large Language Models have two core abilities that make them so versatile:
Language generation- LLMs can complete sentences, write paragraphs, translate text, summarise long passages, and generate new content based on prompts. The resulting text captures patterns and nuances that make it remarkably human-like.
Language understanding – LLMs can answer questions about a passage, classify the sentiment or topic of text, extract key entities, and more. Their contextual comprehension enables robust natural language understanding.
Combined, these skills allow LLMs to power conversational AI applications, translate between languages, summarise documents, moderate content, and automate many writing tasks. The possibilities are vast once an LLM is fine-tuned for a specific domain.
Some well-known examples of LLMs include Google’s BERT, OpenAI’s GPT-3, Meta’s OPT, and Anthropic’s Claude. Each model builds upon previous breakthroughs to achieve new state-of-the-art results on language tasks.
A Scalable Foundation
What gives LLMs their impressive capabilities? Three key ingredients:
- Massive datasets – LLMs are trained on gigantic text corpora, like the internet, containing billions or even trillions of words. This massive volume of data exposes the model to the comprehensive vocabulary, grammar, and patterns of natural language usage. The model learns by predicting masked words and next words in sentences across this vast dataset.
- Deep learning – LLMs utilize powerful neural network architectures to dissect complex linguistic relationships within the training data. They detect subtle nuances in how words relate to one another based on the surrounding context. As the model scale increases – more layers, more parameters – it can capture higher-level patterns and semantic relationships. This enables models to generate incredibly human-like text.
- Self-attention – LLMs are built on transformer architectures that employ self-attention mechanisms. Self-attention allows the model to learn contextual representations of words by weighing their relevance against all other words in the input text. This gives the model a robust, dynamic understanding of how each word relates to the broader context. The transformer’s parallelizable structure also allows self-attention to be calculated efficiently over long sequences in parallel.
Together, the massive scale and dimensionality of training data, deep neural network architectures to extract hierarchical relationships, and self-attention for contextual understanding give rise to the unique language capabilities of large language models. These ingredients enable models to achieve remarkable fluency, coherence, and contextual relevance when generating text.
Under the Hood
LLMs leverage a transformer-based neural network architecture. Here are some of the key components under the hood and how they work:
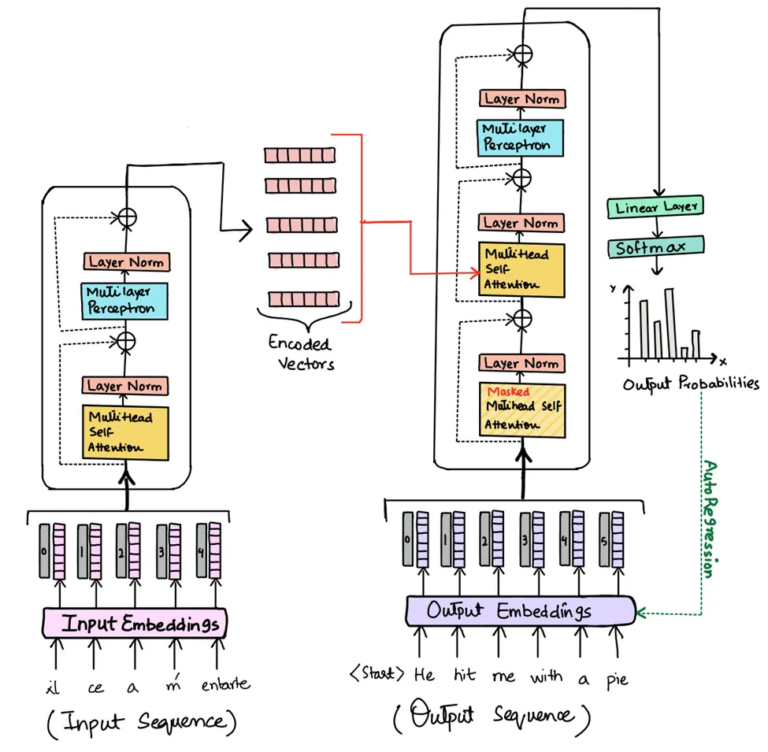
- Embeddings – Words from the input text are converted into numeric vector representations that encode their meaning. For example, a 300-dimensional embedding for the word “apple” could be [0.1, 0.3, 0.2, 0.7, …, 0.5]. The values in the vector are learned to situate words in a high-dimensional semantic space, where words with similar meanings end up clustered closely together. This allows mathematical comparisons using cosine similarity – words with more similar vectors are deemed closer in meaning. For instance, embedding for the word “orange” could be: [0.2, 0.4, 0.1, 0.6, …, 0.6].
Now “apple” and “orange” have similar vectors since they both represent fruits, while “car” has a very different vector far away. This embedding layer maps words to points in a geometric space that corresponds to their semantic relationships. By encoding meanings mathematically, embeddings enable LLMs to learn nuanced linguistic relationships and perform complex analogical reasoning in this learned feature space. The embedding layer thus provides a crucial foundation for the impressive capabilities of large language models.
- Encoders – The encoder applies self-attention layers which process the input text tokens and their embeddings. Self-attention identifies which other words in the sequence are most relevant to understanding the current word. For example, in the sentence “The boy walked to the store”, self-attention would relate “boy” to “walked” based on their contextual relationship.
- Decoders – The decoder generates text output one token at a time based on predicted probability distributions. At each step, it predicts the most likely next word by considering the previous words generated and their embeddings. For example, if the previous words were “The boy walked to the”, the decoder may predict “store” as the next most probable word.
- Heads – Transformers have parallel attention “heads” which focus on different aspects of the input. For example, one head may focus on grammar, another on key entities, etc. This provides multiple “perspectives” on the input to enrich understanding.
- Layers – Stacking multiple transformer blocks with residual connections forms the full model. Higher layers can extract more complex features and relationships in the text, like topic and tone. This gives the model a hierarchical understanding.
Why Large Language Models Matter
LLMs represent a paradigm shift in natural language processing. Their capabilities are enabling several advancements:
- Help democratize AI – With LLMs, anyone can query a model in natural language to generate written content or gain insights from data, without needing to code or have AI expertise. This makes AI capabilities more accessible to the general public.
- Enable more natural interfaces – LLMs allow for free-form conversational interactions rather than rigid command-based interfaces. This facilitates richer, more natural communication between humans and machines.
- Unlock new applications – LLMs can be fine-tuned for specialized tasks like summarizing legal documents, analyzing healthcare records, or assisting customer service agents. This creates new opportunities to automate language-related workflows.
- Reduce bias – With careful data selection, augmentation, and controlled noise injection, problematic biases that exist in training data can be reduced in the model. This can mitigate issues like gender, race, and other biases.
- Increase accessibility – LLMs can generate translations, summaries, and transcripts, making information more accessible to different languages, reading levels, disabilities, and learning preferences.
Despite their promise, concerns around bias, safety, and environmental impact remain. Responsible development and use of LLMs is critical as they become more capable and widespread.
Looking Ahead
The rapid innovations in large language models point to an exciting future filled with possibilities. As research continues, we are likely to see specialized Large Language Models emerge that are fine-tuned for specific professional domains like law, medicine, engineering, and customer service. These custom models will provide enhanced assistance for tasks like contract review, medical diagnosis, design specifications, and customer interactions. Additionally, multimodal LLMs capable of processing images, speech, and video alongside text will enable more natural forms of communication.
LLMs will become compact and efficient enough to be deployed on phones and edge devices, enabling local speech and language features. One especially promising direction is combining the strengths of both humans and LLMs via interfaces for hybrid intelligence augmentation.
This could enable faster and better decision-making, analysis, content creation, and more. While challenges around bias, safety, and responsible use remain, the next decade of LLM innovation promises to unlock its full potential. If research continues apace, LLMs may soon become versatile assistants that enhance nearly every facet of work and life. But care must be taken to develop and use them thoughtfully given their rapidly evolving capabilities.
Conclusion
LLMs represent a new frontier for AI capabilities. Their ability to generate amazingly human-like text and understand nuanced language makes them uniquely powerful. While not without risks, LLMs promise to enable more natural human-machine communication and unlock new applications across industries. With responsible development, these models may profoundly enhance how humans collaborate with AI. This combination of comprehension and generation makes LLMs uniquely versatile AI systems with a wide range of applications.